Google Reader Filter is a Greasemonkey script that lets you define a list of keywords you're interested in and a list of uninteresting keywords. The script highlights the posts that include your favorite keywords in the title and grays out the posts that contain keywords from the blacklist. You can use regular expressions for defining complex restrictions, like dates or long titles.
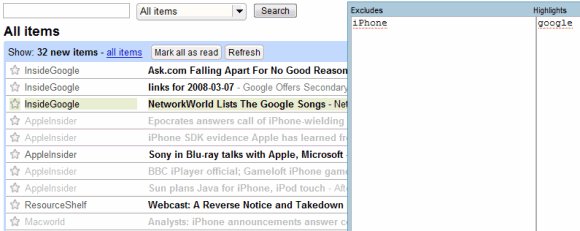
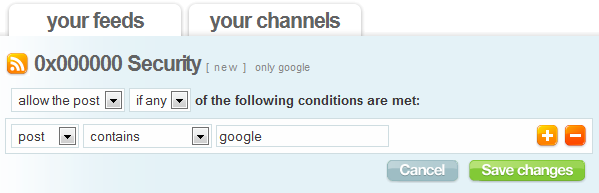
The script doesn't remove posts, so it's more like an automatic highlighter. Feed Rinse has another approach: add a feed, define a list of simple rules for filtering and you get a filtered feed that can be added to your feed reader. For some reason, I couldn't subscribe to Feed Rinse's feeds in Google Reader, even though they were valid and any other feed reader accepted them. Hopefully, it's just a temporary problem.
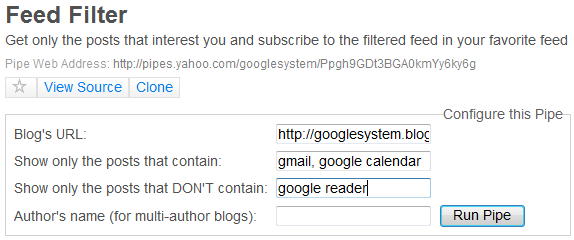
You could also use a Yahoo Pipe that lets you define a list of keywords that are potentially interesting. So if you enter gmail, google calendar as a filter, the pipe will obtain a list of posts that contain Gmail or Google Calendar. After running the pipe, click on "More options", select "Get as RSS" and subscribe to the feed. As Yahoo doesn't allow you to change the feed's title, you should rename it in Google Reader.

Or you can also filter your RSS feeds manually:
ReplyDeletehttp://www.readwriteweb.com/archives/6_ways_to_filter_your_rss_feeds.php
personally, I prefer that, as I cannot enjoy the benifits of greasemonkey while I keep changing computers.
If you create your own yahoo pipe, you can name it anything you want...
ReplyDeleteThe question is... why are 3rd party developers more likely to come up with new Google Reader innovations than the Reader team, when it's so obvious it should be done?
ReplyDeleteAlmost all of my rss feeds are grouped and filtered through yahoo pipes. It makes life so much easier. Especially in my low-importance news feeds. Anything that allows me to filter out any news about Britney and Lohan is good with me ;)
ReplyDelete@Louis Gray:
ReplyDelete* The number of "third-parties" is much bigger than the number of members in the Google Reader team.
* "Third-parties" don't have to integrate a feature or make it scale.
I updated the pipe to support negative restrictions and filtering for the author's name.
ReplyDeleteAnother great tool for feed readers is Feed43 (Feed for free), which lets you turn any web page into an RSS feed. The feed creation may be somewhat confusing for a novice, but if you know your way around HTML it's great for those web sites that have a 'news' page but don't provide a feed.
ReplyDelete(I'm not associated with Feed43, just a happy user!)
I just started using Feed Rinse and I can confirm that it works fine with Google Reader.
ReplyDelete@Matt:
ReplyDeleteI can't add any feed from Feed Rinse. Google Reader shows this message: "No feed available for http://feedrinse.com/services/...".
How to customize (links color, background) this kind of page:
ReplyDeletehttp://www.google.com/reader/shared/user/12863411747128416240/state/com.google/starred
I found css file, but how to edit it?
Is there anyway one can prevent, say, posts with embedded videos from either being delivered or (preferably) being delivered with the videos excised? I tried to do so in Yahoo! Pipes a few months back, but couldn't figure out how to use non-textual content-based mechanisms.
ReplyDeleteIt appears that Google Reader will work with the links from the OPML file (just open in an XML editor and copy out all the "xmlUrl="http://feedrinse.com/services/rinse/?rinsedurl=..." strings), but won't work with reading list link. I suspect the problem is with FeedRinse, since my link is an undifferentiated "http://feedrinse.com/services/readinglist/?mid=".
ReplyDelete"Blacklist" is an a racially offensive term. You are, of course, free to use whatever language you choose, however you are now aware that this type of negative may offend.
ReplyDeleteI use http://www.filtermyrss.com which is a free tool with no sign-in required. It can filter for a keyword or string of keywords.
ReplyDeleteThis is a feature I've been waiting for a long time Google Reader team to implement, but apparently we only have the third party tools to accomplish this.
ReplyDeleteI've been using Yahoo Pipes for a long time now and I'm quite happy with it, I've also tried Feed Rinse and its simple user interface is better suited to the novice user.
However, I see a problem about using any of these third party tools (with the exception of the Greasemonkey script Google Reader Filter): Sharing of filtered feeds is a mess. If I'm following a blog of several authors and I filter to read only a selection of them (filtering on the author filed) I get a different feed then the original one. So, if I share an article from that feed and a friend of mine wants to subscribe to the feed, she will subscribe to the filtered feed and not the original feed, which may be more appropriate for her.
Although filtering is a long missed feature and I manually filter my feeds all the time I would still like Google Reader team to implement it for the sake of its social implications.
To filter feeds by number of "likes" you can use Google Reader Like Filter at http://like-filter.appspot.com
ReplyDeleteThere's no way I'm going over my *hundreds* of feeds and sending them through a third-party filter. This articles misses the point. I need global filters on all my Reader content, implemented by Google.
ReplyDeleteChristmas wish - a Reader filter mechanism. Plz!
ReplyDeleteCheck out JReader, it filters unwanted RSS post and notifies watched items http://jyvee.com
ReplyDelete