Reworking the navigation links for a site
Google shows four internal links for the top result, when they are available and also relevant. Usually, they are the most popular links. This is a great way to compress a big list of navigation links. Google detects navigation links by looking at groups of links that belong to a phrase.
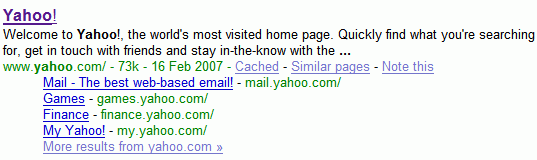
Finding definitions
Google mines the web to find glossaries. Most of them use the DD tag, so it's pretty easy the detect them. The result: you find definitions that aren't available in traditional dictionaries or encyclopedias. You can find definitions by adding define: in front of your query.
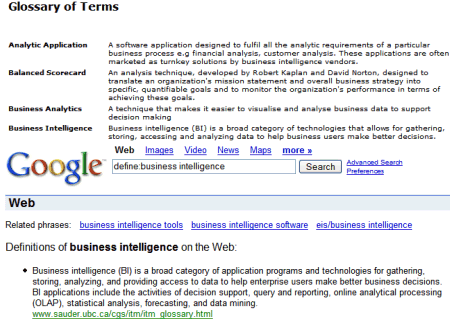
Spell checking
"Google's spell checking software automatically looks at your query and checks to see if you are using the most common version of a word's spelling. If it calculates that you're likely to generate more relevant search results with an alternative spelling, it will ask "Did you mean: (more common spelling)?". Clicking on the suggested spelling will launch a Google search for that term." Google's spell checker recognizes frequent typos, common misspellings, but also terms that are generally confused. So Google is good at detecting misspellings for words that aren't included in dictionaries.
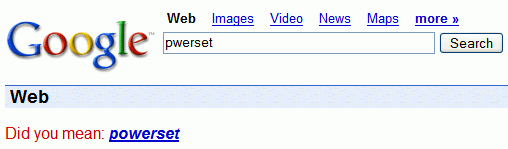
Lists of related terms
Google Sets lets you enter a list of terms and generates related terms. It's a good way to find a list of US presidents, similar illnesses, competitors or movie recommendations. There's no description of the algorithm at Google Sets site, but Google could look at phrases that appear more frequently in a web page, for example in a list.
Universal autocomplete
By looking at popular queries, Google Suggest autocompletes your query, so you type less and also use better queries. This might be extended to a general autocomplete for input boxes, that could be restricted to a domain (for example, music artists).
Google could also mine FAQs (lists of frequently answered questions), create a search engine for files by listing different mirrors and context from the web pages that linked to the files, show related images by mining photo albums, show what sites embed a YouTube video or have frequently updated feeds, or create summaries for web pages by looking at the anchors. When you have hundreds of terabytes of information, the possibilities are endless.

Is there anything you can do to make a site have those multiple listings?
ReplyDeleteI run a theatre site with 9 locations, and a couple of popular common pages that I would like to get listed that way.
Hey neat! UBC was my school... (in your top example)
ReplyDeleteHas anyone experienced a dip in traffic due to having their site listed with "Sitelinks"?
ReplyDeleteThis rumor has been floating around for a while and I am interested to see if there is any truth to it.