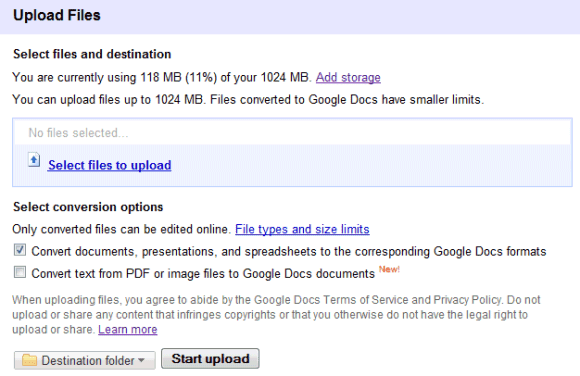
I've tried to convert an excerpt from the book Rework and the result wasn't great. About 10% of the text has been incorrectly converted and the formatting hasn't been preserved.
"This document contains text automatically extracted from a PDF or image file. Formatting may have been lost and not all text may have been recognized," explained Google in a note included in the document.
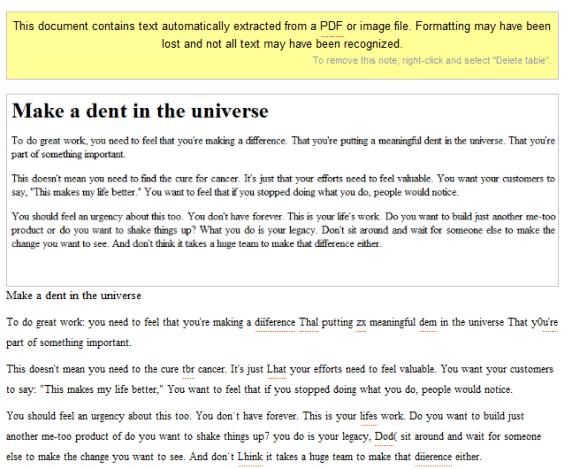
To be fair, ABBYY Online wasn't able to produce much better results:
Update: Google Docs Blog says that this feature only works for the following languages: English, French, Italian, German and Spanish. "For the technically curious: we're using Optical Character Recognition (OCR) that our friends from Google Books helped us set up. OCR works best with high-resolution images, and not all formatting may be preserved."
{ spotted by George }

What about existing PDF's that need OCR???
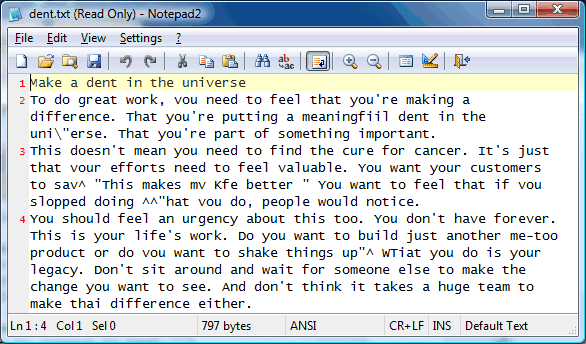
ReplyDeleteIf the alphabetic recognition comes back with "making a diiference", in which "diiference" isn't a recognized English word, their system should be able to match with high probability the garbled phrase to the correct English "making a difference". They could additionally add a comment there with the original OCR result. Also, in the phrase "that you're putting", the OCR has completely removed the word "you're". Given some reasonable probability that a section is a possible word, they could crop out (they know the line height in context) and include an inline image in the document, which when clicked would give the option to replace it with text.
ReplyDeleteAnonymous, pretty awesome and insightful suggestions. I hope Google reads them.
ReplyDeleteI don't see it either, Toby. I don't see why it wouldn't be possible, though (probably will come eventually).
ReplyDeleteWhat blows my mind is that I just found out about this (OCR) and it already works for me ("as is") . . . yet I still don't have the new docs editor/format or the revamped sharing functionality.
How do they "roll out" new features, anyway? By user account or what?
I don't see myself using this. It takes the PDF and creates a Word doc out of it??? I would much rather something like Evernote. The PDF file is preserved but you can still search the text in it (if you are a premium member).
ReplyDeleteI don't think the point is to have a "Word doc;" I think the point is to have a pdf transformed into a dynamic, easily sharable, online document that can be edited with collaborative ease.
ReplyDeleteI think Google's really pushing the collaboration angle with Docs, right now. And as a Sharepoint user when I have no choice, let me tell you, Docs blows it out of the water, when it comes to collaboration. (I won't list all my Sharepoint gripes here, though.)
Nice find
ReplyDeleteAny idea if it supports Japanese kanji?
ReplyDeletehttp://code.google.com/p/ocropus/
ReplyDeletebeen waiting for this to hit
I am using the same OCR library to build qiqqa.com and can testify to the fact that it is an interesting technical problem to know if you should "coerce" the OCR output you see to their nearest English words - especially in scientific literature. Sometimes it makes it worse! But yeah, hopefully frequent triplets like making a diiference" should be reliably alterable!
ReplyDeleteI love to see this progress though!
Jimme
super ... sowas habe ich mir eigentlich von sharepoint erwartet ... analog zu onenote. damit könnte man sehr gut teilenummern von bilder zu fahrzeugteilen extrahieren und in autmatisiert in eine datenbank schreiben ... :)
ReplyDeletehat leider nicht so gut funktioniert: https://docs.google.com/leaf?id=0B8__AElz7h5oODhmMTA1ZjAtYWYxYy00MWQ0LTk1OTItNzVkODdkZTAxYzc3&hl=de
ReplyDeleteSame question here. Why dont they use the google n-grams to correct the phrases?
ReplyDeleteDoes anyone know if the OCR being incorporated in Google Docs is the Tesseract engine. I would guess that it is, but I hate to guess.
ReplyDeleteWill there be an API for this functionality?
ReplyDeleteUnfortunately, I have to give a thumbs down, way down.
ReplyDeleteGoogle OCR fails completely (resulting document is empty or contains a single fax number) in contrast with Acrobat 7.0 which completes OCR of image of text that is a mixture of Greek and english and contains email addresses (with latin characters). Acrobat gets all the email addresses (my goal, here).
PS Resolution is not an issue:
ReplyDeleteResolution is 15-20 pixels per character height.
Anonymous said...
Unfortunately, I have to give a thumbs down, way down.
Google OCR fails completely (resulting document is empty or contains a single fax number) in contrast with Acrobat 7.0 which completes OCR of image of text that is a mixture of Greek and english and contains email addresses (with latin characters). Acrobat gets all the email addresses (my goal, here).
June 22, 2010 6:31 PM
Did not work for me either. I tried with a 74-page PDF but the converted doc had only the first couple of pages. It goes nuts when there are tables too.
ReplyDeleteMake no mistake, no OCR on this planet can guarantee 100% correct conversions all the time, including Google's latest entry. This leads to frustration and disbelief. No one tells you that including Google.
ReplyDelete(Unless of course your documents are picture perfect all the time).
Which means you must proofread every comma, fulstop and every character converted - so if you PDF is 75 pages it will be a pain & you will take ages.
Unless its supported by manual prrofreading & line editing OCR may not always work for every one all the time!
Does not work. Does not even tell why.
ReplyDeleteJust says "couldn not upload".
Now what ?
Me parece fatástica la nueva caracteristica añadida a google docs. Esta gente si que sabe aportar valor añadido a sus productos. Que sigan así.
ReplyDeleteThis is a great feature, moreover most of the good OCR tools are sharewares. But some good free OCR tools to Convert Scanned images to Text / Word Documents also available as listed at
ReplyDeletehttp://www.globinch.com/2010/06/08/best-pdf-ocr-tools-to-convert-scanned-images-to-text-word-documents/
How much did Adobe pay you?
ReplyDeletehttp://free-online-ocr.com/ <---good find.
ReplyDeleteTried a TON of OCR software, basically anything that was freely available as a trial or shareware... result is most are barely functional when trying to recover a ton of VBasic code I lost due to computer issue but that I had a printed hard copy of. I did however find a bright light, OCRkit. I found it to be amazingly accurate in preserving the formatting, text, complex equation formats and all small characters. I know its not google, but its almost free compared to the cost of other commercial software (i.e. 50 bucks vs 200-500 for some). If you need this, try it. I am VERY curious about what OCR engine they use and how it is possible that its SO Much better than other presumably polished legacy versions that have been around for years, yet this is a very new software in its second revision....
ReplyDeleteThis is really useful for us students who dont want to print the pdf lecture slides onto paper that the professor has posted, and would like to type the additional notes.
ReplyDeleteBesides Google OCR, I prefer to use other free online OCR services. I highly recommend the free beta software offered by Ricoh Innovations at: http://beta.rii.ricoh.com/betalabs/content/document-conversion
ReplyDeleteWOW! I was officially sock-less after I did this:
ReplyDelete1) Scanned a 2-page paper doc (some plain text, some texty images) at 300dpi to 'blind' PDF [800kb]. Blind meaning no searchable text, just an image.
2) Input PDF to free-online-ocr (FOO).
3) Output as PDF [1800kb](yes, it sounds silly, thus it was the last combo I tried)
4) It looked exactly like the original. Searched for words that FOO and Google Docs (GDX) had trouble converting to text formats in previous combos. No trouble. As far as I can tell EVERY word in this PDF (although not in the images in the PDF) was searchable. This is where I lost my sox.
5A) Uploaded to GDX without conversion to GDX format. Every word remained searchable.
5B) Uploaded to GDX WITH conversion to GDX format...all the trouble words are messed up again.
Moving forward I'll convert 'blind' pdfs to searchable pdfs via FOO then upload to GDX for searchable storage.
I think that http://www.e-ocr.com resolve this problem.
ReplyDeleteOCR is important too, but as long as "fuzzy search" works to a point where you can find the keywords you search on... then that would be a good feature as well. I know it doesn't help those looking to convert documents to text, but I am specifically look at archiving documents and being able to search on them when the need arises.
ReplyDeleteWonder how good Google OCR is - I uploaded an 88 page patent file and it seems I can seach down to page 10. Haven't looked at the fidelity or anything yet. But bummer, seems to stop after page 10... I'll wait and see if time will convert more - but doubt.
ReplyDeleteyes this is really helpful content. please check my site .. my website is free ocr online tool..http://getlatestthings.com/
ReplyDelete