 After a Belgian press organization sued Google for copyright infringement and won, World Association of Newspapers decided to create "an automated system for granting permission on how to use their content", reports Reuters. The system will be called Automated Content Access Protocol (ACAP).
After a Belgian press organization sued Google for copyright infringement and won, World Association of Newspapers decided to create "an automated system for granting permission on how to use their content", reports Reuters. The system will be called Automated Content Access Protocol (ACAP).If you're wondering why a such a system would be useful, you're not the only one. "Since search engine operators rely on robotic 'spiders' to manage their automated processes, publishers' Web sites need to start speaking a language which the operators can teach their robots to understand. What is required is a standardized way of describing the permissions which apply to a Web site or Web page so that it can be decoded by a dumb machine without the help of an expensive lawyer."
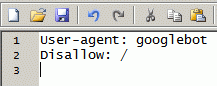
The publishers seem to ignore the fact that there is a system that lets you control what pages you want search engines to crawl: it's called robots.txt and it's available to every site owner. Probably some sites have an extremely valuable content and they need a new permission system, that will match their inflated self-importance.
Publishers were kind enough to offer an example: "In one example of how ACAP would work, a newspaper publisher could grant search engines permission to index its site, but specify that only select ones display articles for a limited time after paying a royalty." It's very strange to see this example. If you allow a search engine to crawl your site, you also allow it to display a small excerpt from the article (or at least the headline). If a site pays you to display the full articles (like Yahoo News), that site already knows it has the right to republish the content. Other sites, like Google News, send the visitors to the source of the article and they only aggregate and cluster articles.
I think news sites should be treated the same like the rest of the sites, and it's not necessary to create a new system for giving permissions to index a site.
Related:
Google Belgium homepage displays the court order
More about Google News

You hit the nail on the head there.
ReplyDeleteI really hate seeing people who clearly doesn't have a clue about how things work start making decision.
I totally agree, as you aptly put it, the inflated ego's and ignorance of the internet shown by these agencies is truly astounding at times. Google for one only brings customers to the news sites and so increasing their readers and so revenue. I fail to see the problem and the mindset of the people behind it.
ReplyDeleteI have to say that I really hope that this doesn't set a precedent. The copyright duels that have been going on are astounding in their 'interpretation' of copyright law, and how it affects Search Engines. I mean - how the hell do they expect people to find their site if nobody finds it in a search engine?
ReplyDeleteThe collateral to this is the likes of the Baen Free Library, where they have taken (As far as I'm concerned) the right approach - there's no such thing as bad publicity.
Somebody needs to rub a few of these agencies noses into that site, good and hard.
Aaarrrgggggg!!! Just wait!!! Soon they will start suing bloggers for quoting their "copyrighted material" on a blog.
ReplyDeleteToo bad that these newspaper agencies are more interested in minting money than dessiminating vital information. If they are so concerned, why put it on the web in the first place. Why not use pigeons to drop in the latest happenings??
ReplyDelete